


Guide pour automatiser à 100% ton SEO [Partie 1]
Dans cette première partie on voit en détail l'automatisation pour générer tes articles en analysant les 1ers résultats de Google pour chacun de tes mots-clés

Si tu es nouveau ici, sache que nous construisons un SaaS de type Landing Page Builder de 0 à 1M€ en 1 an.
Et que je partage chaque semaine les coulisses du projet et des astuces marketing et stratégiques pour développer un logiciel SaaS 😉

Il a neigé récemment ❄️. Ça faisait longtemps 😁.
Et ça fait surtout bizarre parce qu'avec ma femme on avait voyagé pendant plus de 20 mois, majoritairement dans des pays chauds.
Le retour au froid est difficile 🥶Point sur l’avancement :
✅ L’architecture du projet est faite et permettra d’avoir un outil 100% temps réel
✅ Le moteur de génération des pages est fait
Je suis en train de travailler sur l’interface de l’éditeur
✅ Les maquettes sont faites
Je suis en train de développer l’interface
Ça y est ! On entre dans le vif du sujet. On va mettre en place l’automatisation qui va nous permettre de mettre en marche notre stratégie SEO et générer les articles.
Ce sujet va être divisé en 3 parties, celle-ci étant la première.
Le lien vers les parties suivantes sera mis à jour au fur et à mesure dans le sommaire ci-dessous :
Les étapes de l’automatisation (article actuel)
Si l’automatisation complète t’intéresse n’hésite pas à me le dire (par mail ou commentaire) et je te l’enverrai volontiers ! (Oui, même si les 3 parties ne sont pas encore disponibles 😉).
Voici un aperçu de ce que ça donne une fois terminée 😁
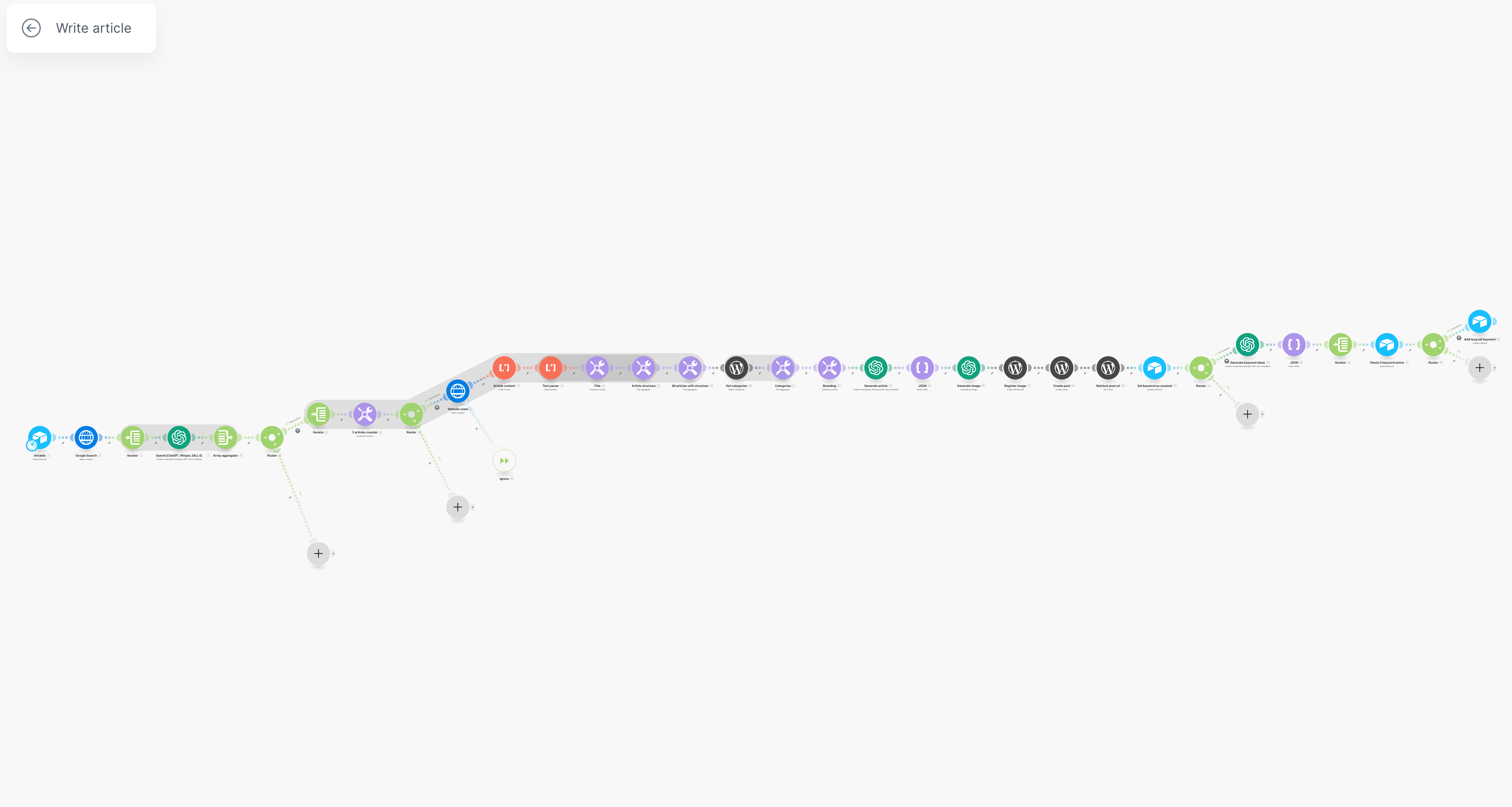
La stratégie en mettre en place dans l’automatisation
Dans cette première partie on va voir en détail toutes les étapes de l’automatisation que l’on va mettre en place et de ce que ça implique.
Dans les 2e et 3e parties on verra plus en détail les prompts de génération ainsi que la stratégie de sélection des mots-clés pour lesquels on veut générer les articles.
Alors que cherche-t-on à faire avec cette automatisation ?
Eh bien l’objectif est simple : choisir un mot-clé et générer un bon article pour ce mot-clé.
Ok, mais comment est-ce qu’on va faire ça ?
Qu’est-ce qu’un bon article déjà ?
Toutes les formations en SEO que j’ai suivies sont d’accord sur cette dernière question : un bon article est un article qui répond correctement à la demande du visiteur.
Ça veut dire que l’article doit être en accord avec l’intention de recherche :
Est-ce que le visiteur cherche une information sur un sujet ?
Est-ce que le visiteur cherche à acheter un produit ?
etc…
Et comment est-ce qu’on détermine ça ?
Eh bien on fait confiance à Google ! 😁
Eh oui, Google connait cette intention de recherche et va positionner en premières places les articles qui y répondent.
Donc pour connaître cette intention de recherche, il suffit de regarder les premiers résultats de recherche.
Par exemple, si je cherche “barbecue” :
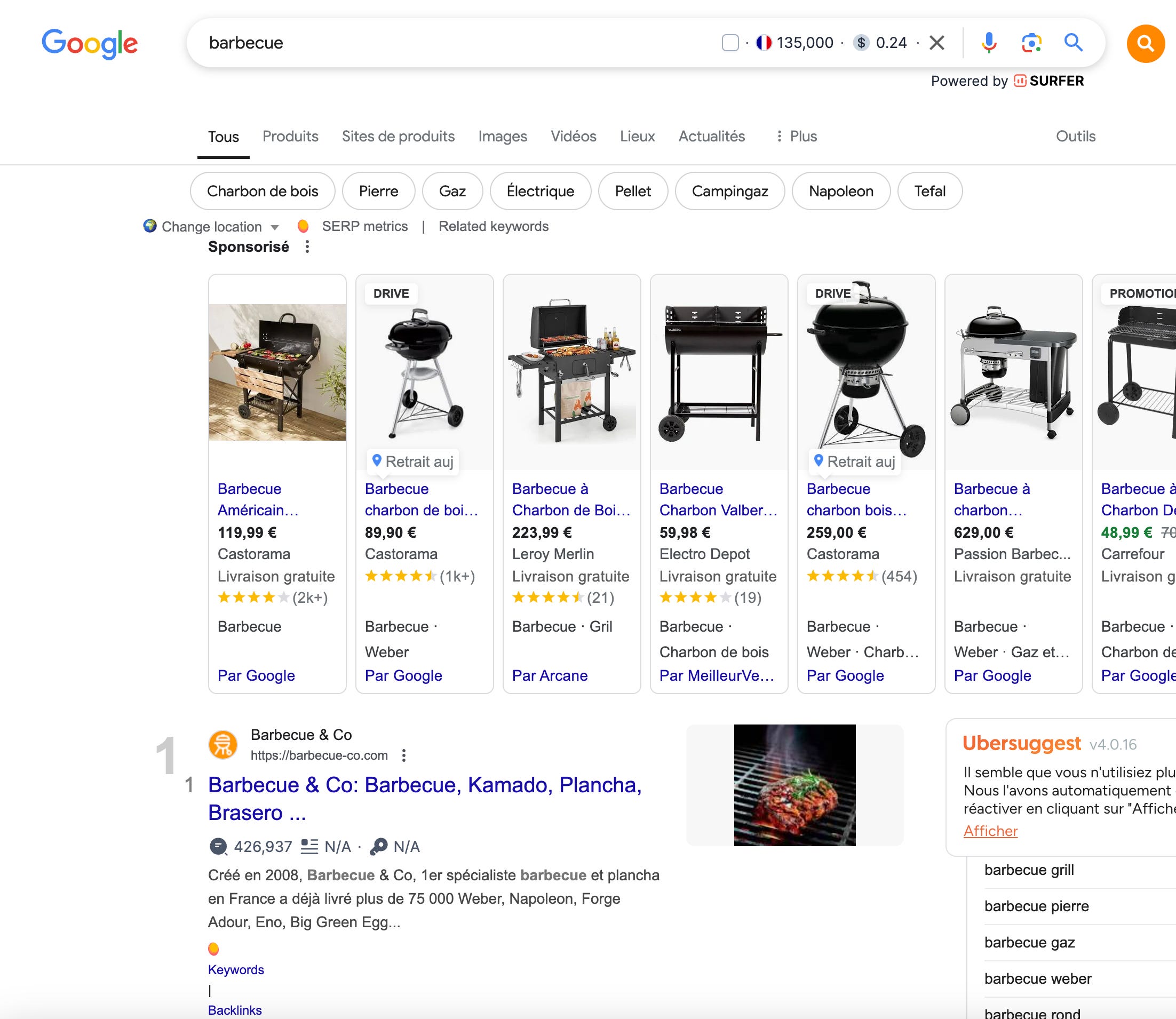
On voit clairement que l’intention est l’achat.
Mais si je recherche “landing page” :

On voit que l’utilisateur recherche plutôt des informations (le premier résultat était aussi de l’information, je ne l’ai pas mis parce qu’avec les résultats enrichis on ne voyait que ce résultat 😅).
Ok, donc on veut connaître l’intention de recherche.
Et ensuite ?
On va s’inspirer un maximum des articles qui ont une bonne position dans les résultats de recherche :
📰 Leur titre
🧩 Leur structure
📄 Leur contenu
Puis on va générer un article qui fait mieux.
Enfin, on va enregistrer cet article sur le blog.
Donc si on récapitule :
🗝️ On récupère un mot-clé
🔍 On fait une recherche Google avec
📋 On scanne les 3-4 premiers résultats
📰 On récupère leur titre
🧩 On récupère leur structure
📄 On récupère leur contenu
🤖 On donne tout ça à l’IA + des infos sur notre branding pour générer un article
🖼️ On lui demande aussi de nous générer une image d’illustration
💾 On enregistre tout ça sur le blog
Ça paraît simple comme ça, mais on va voir que ça ne l’est pas autant 😅.
C’est parti !
L’automatisation en détail
On va utiliser l’outil Make pour l’automatisation car il est vraiment très bien fait pour ce genre de choses 😁.
Récupérer le mot-clé et les premiers résultats de recherche

On le verra plus en détail dans la partie 3, mais notre stratégie de mots-clés va se passer dans Airtable, une sorte de Excel++ dans lequel on peut filtrer et avoir des relations entre les tableaux.
Notre automatisation commence donc par récupérer un mot-clé dans notre liste de mots-clés.
Puis on fait une requête HTTP pour récupérer les 10 premiers résultats de recherche dans Google.
Au départ je voulais simplement faire une requête directement sur le site de Google : https://www.google.com/search?q=landing+page puis scraper les résultats.
Mais Google détecte ce genre de requête et rend très difficile le scraping.
Je dois donc passer par leur API spécialisée : Custom Search API.
Cette API permet de récupérer les résultats de recherche de Google, c’est donc exactement ce que je cherchais à faire ☺️.
J’utilise ce point d’API : https://customsearch.googleapis.com/customsearch/v1.
Avec mes tokens d’authentification et quelques paramètres pour chercher les résultats français.
Et derrière, ça me retourne la liste au format JSON (très pratique à interprêter et pris en charge par Make) :
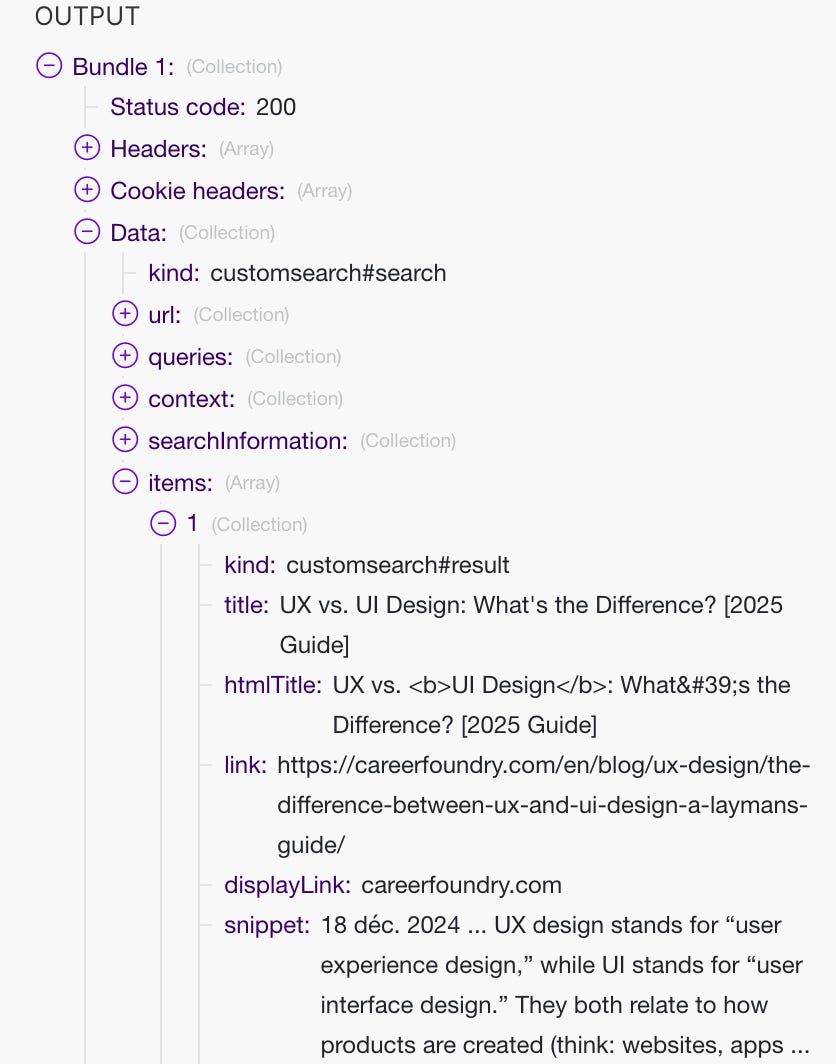
Mais on rencontre un problème en récupérant la liste des résultats de Google pour le mot-clé : il n’y a pas que des article 😱.
On y trouve aussi des landing pages, des offres d’emploi, des pages de vente, des espaces communautaires, etc…
Or, on cherche à écrire un article, donc il ne me faut que des articles pour m’en inspirer.
Pour ce faire, on va tenter de catégoriser chaque résultat grâce à l’IA, puis on ne va garder que les articles.
Je passe par un iterateur pour que chaque élément de ma liste de résultats soit exécuté indépendemment.
Puis je demande à ChatGPT de me classifier les contenus en ne retournant que le nom de la classification (afin de pouvoir filtrer ensuite).
Ensuite j’utilise un aggrégateur afin de retourner les résultats sous forme de liste, mais en les groupant par catégorie.
Je filtre pour ne garder que la catégorie “article”.
J’incrémente un compteur, puis je filtre encore une fois pour ne faire passer que les 4 premiers articles.
Oui, j’imagine que ça paraît complexe au premier abord 😅.
D’ailleurs je n’ai pas sorti ça de mon chapeau d’un coup. J’en suis arrivé là en rencontrant les problèmes au fur et à mesure et en itérant.
Mais, pour que tu puisses mieux visualiser les choses, voici ce que ça donne :
Quand je récupère les résultats Google j’ai ce qu’on appelle un “Bundle” qui contient les 10 résultats :
Bundle 1 :
Résultat 1
Résultat 2
Résultat 3
etc…
Ensuite je veux que ChatGPT classifie mes résultats.
Je veux donc exécuter ce module pour chaque résultat.
Or, un module s’exécute pour chaque Bundle.
En l’état, il ne va donc s’exécuter qu’une seule fois vu que je n’ai qu’un Bundle qui contient tout.
Il me faut donc un bundle par résultat.
C’est ce que me permet de faire l’itérateur : il prend une liste dans un Bundle et la transforme en liste de Bundles, ce qui nous donne :
Bundle 1 : résultat 1
Bundle 2 : résultat 2
Bundle 3 : résultat 3
etc…
ChatGPT peut donc classifier chaque bundle (et donc chaque résultat) séparément.
Ensuite j’utilise un aggrégateur pour faire l’inverse de l’itérateur et transformer tous mes Bundles en 1 seul Bundle contenant une liste.
Sauf que je veux aller plus loin et grouper mes listes par catégorie.
Ce qui va me donner un Bundle par catégorie, contenant les liste des résultats de cette catégorie :
Bundle 1 : catégorie “Article”
Résultat 1
Résultat 3
Bundle 2 : catégorie “communauté”
Résultat 2
etc…
Cette catégorisation par Bundle me permet ensuite, grâce à un Router, de ne garder que le Bundle de la catégorie “Article”.
Il me restera donc :
Bundle 1 : catégorie “Article”
Résultat 1
Résultat 3
Ensuite j’utilise à nouveau un itérateur pour transformer mon bundle avec une liste de résultats en liste de bundles :
Bundle 1 : résultat 1
Bundle 2 : résultat 2
Chaque bundle va ensuite passer par l’incrémenteur.
C’est un module qui va commencer avec 1, et qui, pour chaque nouveau bundle, va augmenter sa valeur de 1.
Ça me permet, grâce au Router qui suit, de ne garder que les X premiers articles en rejetant tous ceux pour lesquels l’incrémenteur est trop élevé (supérieur au nombre d’articles que je veux garder).
Ouf ! 😮💨
Tout ça pour récupérer les 4 premiers articles dans Google pour le mot-clé sélectionné 😅.
Voyons la suite.
Récupérer et scanner les articles
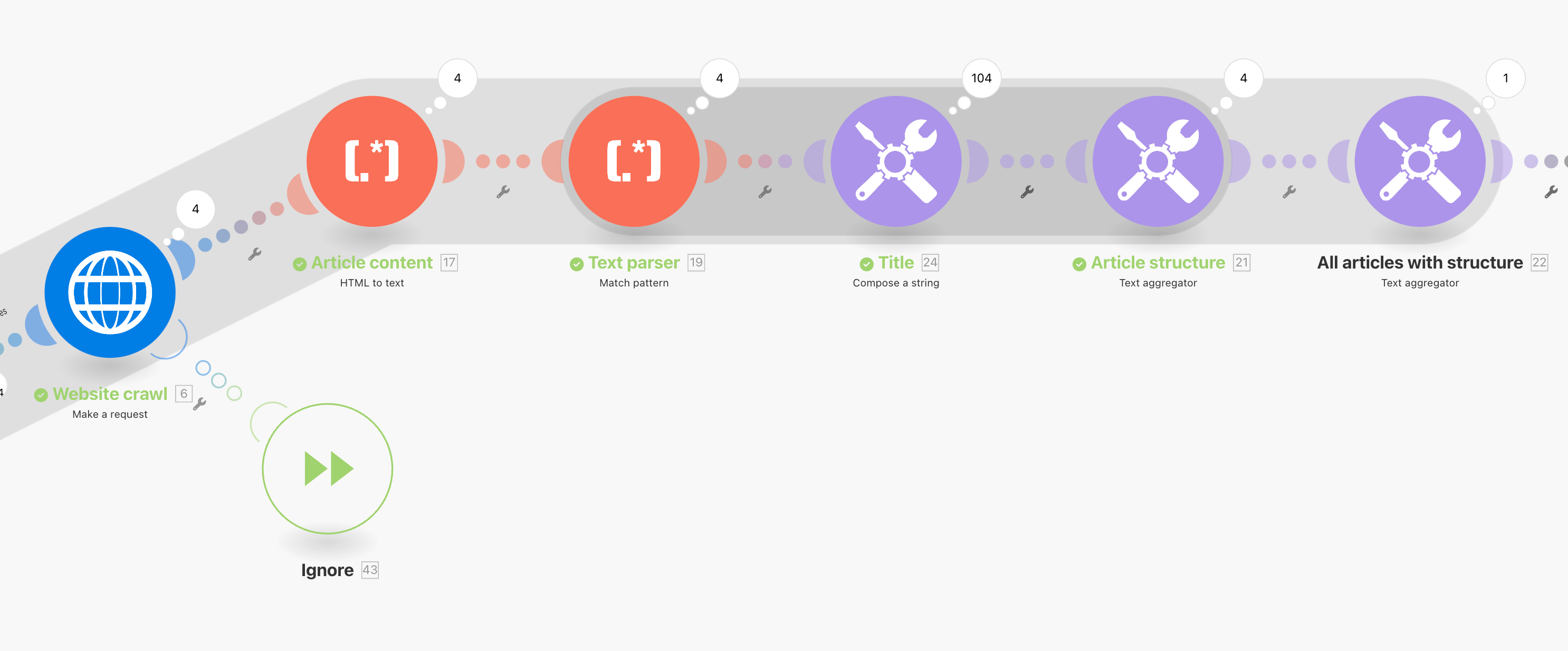
Maintenant qu’on a notre top 4 des articles on veut, pour chaque article :
📄 Récupérer son contenu
🧩 Récupérer sa structure
📰 Récupérer son titre
On va donc commencer par faire une nouvelle requête HTTP sur l’article en question.
Ça va nous retourner son contenu (en HTML).
J’ai demandé à ignorer les erreurs car il peut arriver qu’un site web ne réponde pas ou retourne une erreur. Dans ce cas, tant pis, on continue sans lui.
Ensuite j’utilise un parser qui va me transformer le contenu HTML de l’article en Markdown, beaucoup plus lisible et moins verbeux.
Je récupère tous les titres de l’article, en me basant sur le contenu HTML.
Pour ce faire, j’utilise une Regex qui va me permettre d’extraire les titres :
(<h1[^>]*>(?<h1>[^<]+)</h1>)|(<h2[^>]*>(?<h2>[^<]+)</h2>)|(<h3[^>]*>(?<h3>[^<]+)</h3>)|(<h4[^>]*>(?<h4>[^<]+)</h4>)|(<h5[^>]*>(?<h5>[^<]+)</h5>)|(<h6[^>]*>(?<h6>[^<]+)</h6>)
Ça paraît imbuvable comme ça (et ça l’est 😅).
Mais c’est finalement la même chose qui est répétée pour chaque niveau de titre (de H1 à H6).
Si je ne prends la Regex que pour le H1 ça donne :
(<h1[^>]*>(?<h1>[^<]+)</h1>)
Ce qui veut dire : récupère le contenu que tu trouveras entre les balises HTML <h1> et </h1> et mets-le dans un groupe nommé h1.
Ce qui me permet d’extraire tous les titres et de savoir de quel niveau ils sont :

Ensuite, je cherche à générer un texte qui contient le titre avec son niveau :

C’est aussi assez imbuvable, mais relativement simple : pour chaque niveau de titre je regarde si le titre en question existe, si c’est le cas je l’utilise en le préfixant par son niveau, sinon je vérifie le niveau suivant.
Si j’ai un titre “Courses” de niveau H2, ça me donnera :
H2: Courses
Puis j’utilise un aggrégateur de texte pour rassembler tous mes titres en un seul Bundle. Parce que comme tu peux le voir sur la capture plus haut, chaque titre trouvé est mis dans un nouveau Bundle. Or, je ne veux qu’un seul Bundle avec tous mes titres à la ligne.
Ça va me donner ça :

J’ai donc extrait la structure de l’article.
Enfin, j’utilise un autre aggrégateur de texte, mais cette fois-ci pour regrouper mes 4 articles en un seul texte.
J’avais 1 Bundle par article, je ne veux plus qu’1 seul Bundle contenant tous les articles.
Je demande à créer le texte comme suit pour chaque article :

Ça me permet d’avoir un texte qui contient, pour chaque article, son numéro, son titre, sa structure (décortiquée juste avant) et son contenu.
Pour ce dernier j’utilise une condition pour n’ajouter le contenu que du premier article afin d’éviter que ce texte soit trop long (tu en sauras plus dans la prochaine partie 😉).
Ajouter quelques informations utiles avant de générer l’article

Avant de générer l’article j’avais envie de récupérer quelques informations supplémentaires :
📂 La liste des catégories dans mon blog (comme ça on demandera à l’IA de sélectionner la meilleure)
✏️ Un texte pour décrire mon Branding
Pour la liste des catégories il s’agit simplement d’utiliser le module de Wordpress pour les récupérer.
Étant donné que ça me retourne 1 Bundle par catégorie, j’utilise ensuite un aggrégateur de texte (tu commences à connaître maintenant 😁), pour n’avoir plus qu’un seul Bundle qui contiendra toutes les catégories sous cette forme :

Ce qui donnera quelque chose comme ça :

Et pour le Branding, c’est un simple texte. J’ai voulu le mettre dans son propre module afin de le modifier plus facilement au besoin 😉.
Générer l’article et son illustration
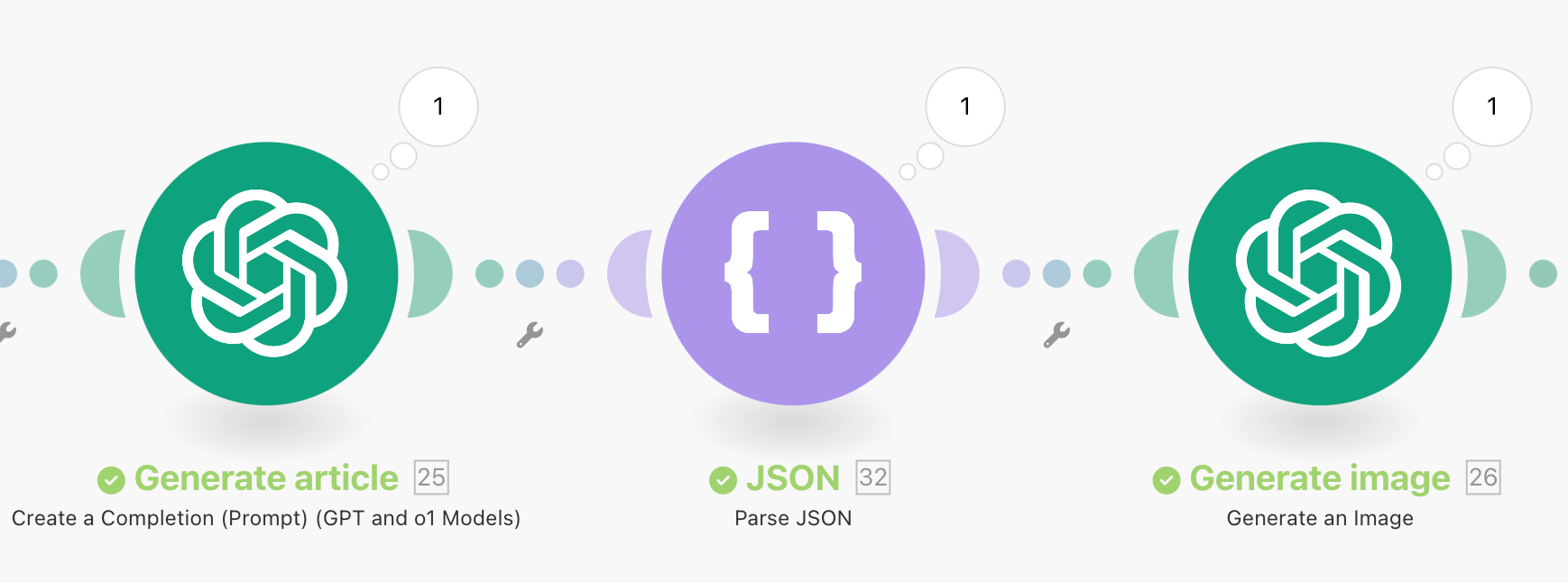
On y arrive enfin ! 😅
On va approfondir ça dans la prochaine partie mais on va utiliser l’IA pour lui donner tout ce qu’on a et lui demander de générer un article.
Sauf qu’on veut qu’il nous génère plusieurs choses :
📝 L’article
📰 Un titre
📂 Le choix de la catégorie
✍️ Le résumé de l’article
🔗 Le slug pour l’URL de l’article
Il va donc falloir être capable d’analyser ce qu’il nous dit. Et pour ça on va lui demander de générer sa réponse au format JSON 🤩.
En lui précisant, bien-sûr, comment faire.
Comme ça, on a juste à utiliser un module de parsing JSON.
On lui fournit la structure attendue et on se retrouve avec ce qu’on veut, dans un format exploitable :

Et ensuite, on demande à l’IA de nous générer une image pertinente par rapport à l’article généré.
On enregistre l’article sur notre blog

C’est notre dernière étape pour cette première partie (on ira un peu plus loin dans la partie 3 😉) : Enregistrer l’article.
Dans un premier temps, on va demander à enregistrer l’image générée dans Wordpress.
Puis, on enregistre l’article avec ces informations :
📰 Le titre
📄 Le contenu HTML
✍️ Le résumé
📅 La date
🛠️ Le statut (“Brouillon” pour que je puisse le relire avant de le publier)
🔗 Le slug (pour l’URL)
🖼️ L’image
⚙️ Des paramètres Rank Math en passant par les métadonnées Wordpress : 🔑 Le mot-clé (rank_math_focus_keyword) 📝 Le titre (rank_math_title) 🖋️ Le résumé (rank_math_description)
Je récupère ensuite les informations sur l’article nouvellement créé (parce que le module de création ne nous retourne que son identifiant).
Puis je mets à jour le mot-clé dans Airtable (on voit ça partie 3 😉)
Et maintenant ?
Ça fait déjà un gros morceau à digérer 😅.
J’espère que c’était suffisamment clair.
Encore une fois, si tu es intéressé par l’automatisation tu peux me la demander et je te l’enverrai 😉.
Dans la prochaine partie on va aller plus en détail sur les prompts IA qui ont été utilisés dans l’automatisation.
Et dans la partie 3 nous verrons comment on va gérer les mots-clés pour notre stratégie SEO.
À très vite ! 😉